About
I am a Master's student in CS at the University of Michigan, Ann Arbor.
My research interests revolve around Multimodal AI, 3D Vision, and world models.
I am currently working with
Dr. JJ Park on generation of high-quality 3D meshes for simulation, CFD, etc.
I have previously interned at
Kiwi,
Upthrust and
AarogyaAI on research, multi-agentic softwares and data science projects.
Paper Implementations
CLIP-ViL-GradCam
A PyTorch implementation of CLIP-ViL from the paper
"How Much Can CLIP Benefit Vision-and-Language Tasks?" from the authors
Sheng Shen, Liunian Harold Li, Hao Tan, Mohit Bansal, Anna Rohrbach, Kai-Wei Chang, Zhewei Yao, Kurt Keutzer
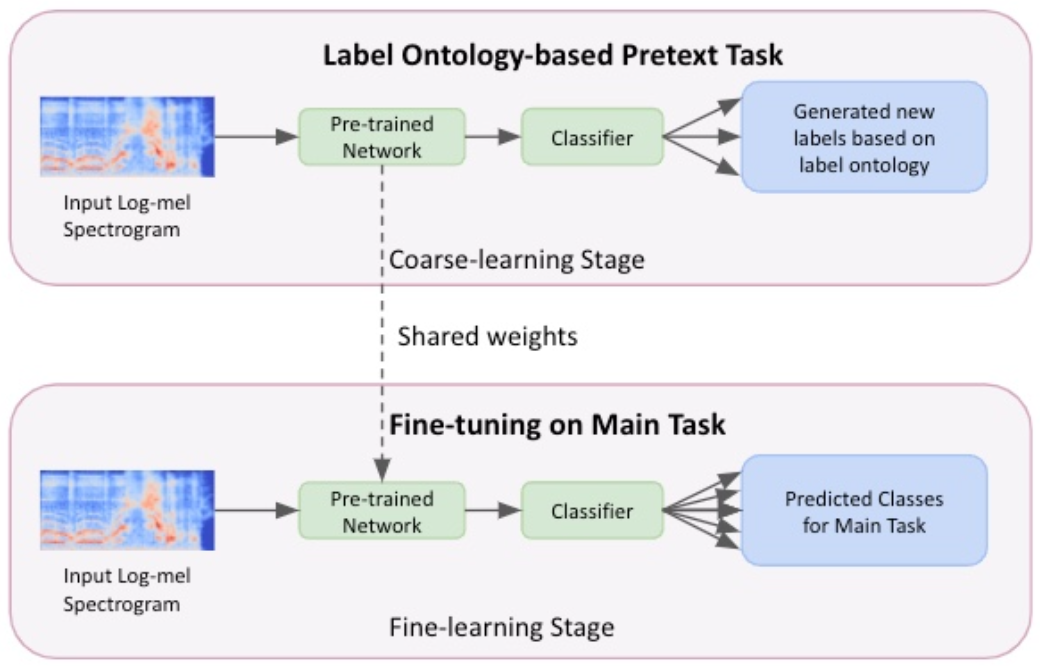
SimCLR-UrbanSound8K
A PyTorch implementation of SimCLR from the paper
"A Simple Framework for Contrastive Learning of Visual Representations" from the authors Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton on the UrbanSound8K dataset.
Trained only on the first fold, due to inadequate computation power and produced an accuracy of 81% on melspectrogram images.
CLIP
A PyTorch implementation of CLIP from the paper
"Learning Transferable Visual Models From Natural Language Supervision" from the authors Alec Radford et al. Implemented the main architecture of the model and trying to extend this architecture for VQA tasks.
MusicLM/AudioLDM
A PyTorch implementation of MusicLM and AudioLDM from the paper
"AudioLDM: Text-to-Audio Generation with Latent Diffusion Models" from the authors Liu et al on the MusicCaps dataset.
Faced some errors to train the MusicLM model and currently trying to resolve them. Trained the AudioLDM model by finetuning it from the huggingface library on the melspectrogram images of the MusicCaps dataset.
Siamese Network with Triplet Loss
A Tensorflow implementation of Siamese Network architecture with Triplet Loss from the paper
"FaceNet: A Unified Embedding for Face Recognition and Clustering" from the authors
Florian Schroff, Dmitry Kalenichenko, James Philbin.
Trained the model on the Ship Classification dataset which I scraped from
Ship Spotting to make an
Indian Ships Dataset uploaded on Kaggle.
AI Algorithms
Implementations of some basic AI algorithms like Gradient Descent and K-means with real-time visualization from scratch using NumPy and Matplotlib.
Side Projects
AI Wordle Solver
Predict the next best word to play on Wordle by giving a screenshot of a partially-filled Wordle.
Search Browser History GPT
Query the content of your search browser history to navigate to the desired webpage.
Splitwise GPT Vision
Give an image of a bill and automatically add SplitWise entries directly into the app.
Genetic Handwritten Digits
Use genetic algorithms to evolve the CNN architecture, convolution kernels size and pooling to classify handwritten digits.
Face Recognition LFW
Used FaceNet embeddings to train SVMs using one-vs-all and one-vs-one approach to classify the LFW dataset over 86 faces.